AI agents in production: why most prototypes never ship
The demo is the easy part. The hard part is making it safe enough to leave running.
Iago Mussel
CEO & Founder
The prototype worked. The agent read the ticket, queried the database, wrote the report, and emailed the summary. Everyone in the room saw the future.
Then someone asked the obvious question: can we turn this on for real customers? That’s when the conversation shifts from capabilities to consequences. What happens when it deletes the wrong record? What happens when it loops? What happens when someone prompts-injects the ticket description? The demo didn’t have answers. Production demands them.
Most AI agent prototypes never ship because the gap between demo and production is larger than teams expect. It is not a matter of adding tests and calling it done. It is a redesign of how the agent thinks, acts, and is held accountable.
Prototypes hide the hard problems
A prototype is optimized for the happy path. The inputs are clean, the tools respond as expected, and the human is watching. In production, inputs are messy, tools fail silently, and the agent runs unattended for hours.
The prototype also hides cost. A ten-step agent loop that calls an LLM three times per step and queries APIs along the way can easily consume thousands of tokens per task. Multiply that by concurrent users and you have a budget problem before you have a scaling problem.
Finally, prototypes hide failure modes. An agent that confidently performs the wrong action is worse than a broken script because it looks like it’s working. Deterministic automation fails in obvious ways. Agentic systems fail in plausible-sounding ways.
You need boundaries, not just goals
A demo agent is given a goal: “summarize the support tickets from the last week.” A production agent needs boundaries: which tickets it can read, which systems it can touch, how many tokens it can spend, how long it can run, and what it must never do.
Boundaries should be enforced in architecture, not in prompts. Prompts can be bypassed by better prompts. Architecture can’t. The right model is a small, deterministic permissions layer that sits between the agent and every tool it wants to use.
We usually design three permission scopes:
- Read-only tools for research and observation.
- Sandboxed write tools that can propose changes but require human approval.
- Approved automated actions that are reversible and low-blast-radius.
An agent should not discover mid-run that it has write access to production. It should be impossible for it to have that access in the first place.
Tool design is more important than model choice
Teams spend weeks comparing models and days designing tools. That’s backwards. A mediocre model with well-designed tools outperforms a great model with brittle tools.
Good tools are specific, idempotent, and observable. They do one thing, they can be retried safely, and they log what happened. Bad tools are broad, stateful, and opaque — “update the database” is a terrible tool because it hides intent and consequences.
Every tool should expose a contract: inputs, outputs, failure modes, side effects, and whether it’s reversible. That contract is what lets you test the agent in isolation, simulate failures, and audit behavior after an incident.
Evaluation is the new test suite
Unit tests work for code. They don’t work for agents because the output space is too large and the correct answer is often contextual. You need evaluation — systematic scoring of agent outputs against representative cases.
A good evaluation pipeline has:
- A dataset of real tasks with expected outcomes.
- Automatic judges for objective criteria: did the agent complete the task, did it use the right tools, did it exceed token or time limits.
- Human review for subjective criteria: tone, accuracy, safety.
- Regression tests that compare new versions against the old baseline.
Without this, every change is a gamble. With it, you can iterate on prompts, models, and tools with confidence.
Observability means understanding intent
Standard observability tells you what happened. Agent observability needs to tell you why. A trace should capture the goal, the reasoning steps, the tools called, the inputs and outputs, and the final action. If you can’t reconstruct the agent’s decision chain, you can’t fix it.
We log four things for every agent run:
- The original user request and any injected context.
- The agent’s plan and any changes to that plan.
- Every tool call with input, output, and timestamp.
- The final result and any human overrides.
That log is what turns a confusing incident into a five-minute diagnosis.
Human-in-the-loop is a design pattern, not a fallback
The default instinct is to automate everything and add human approval only when something looks risky. The better model is to define which actions the agent can take autonomously and which always require a human.
Autonomous actions are reversible, low-cost, and well-tested. Human actions are destructive, high-cost, or novel. The boundary should be explicit in code, not left to the agent’s judgment. An agent that decides whether to ask for permission is an agent that will eventually decide wrong.
The production checklist
Before turning an agent loose on real work, confirm you can answer yes to these:
- Every tool has a defined contract and limited permissions.
- Token and runtime budgets are enforced by the infrastructure.
- There is a dataset of real tasks with passing evaluation criteria.
- Every run is logged with enough detail to reconstruct decisions.
- Destructive actions require human approval.
- There is a kill switch and a rollback path.
If you can’t check all six, you have a demo with credentials. Not a production system.
Production agents are possible. We build and operate them for clients. But they require the same discipline as any critical automation — just with more uncertain outputs. If your team is trying to cross that gap, our AI automation services cover the architecture, tooling, and governance that make agents shipable.
Share
Related articles
What is an AI Agent — and how is it different from traditional automation?
RPA, GenAI, and autonomous agents are not the same thing. Here's a clear breakdown of what each one actually does — and when to use which.
What is agentic AI — and why the market is moving in this direction
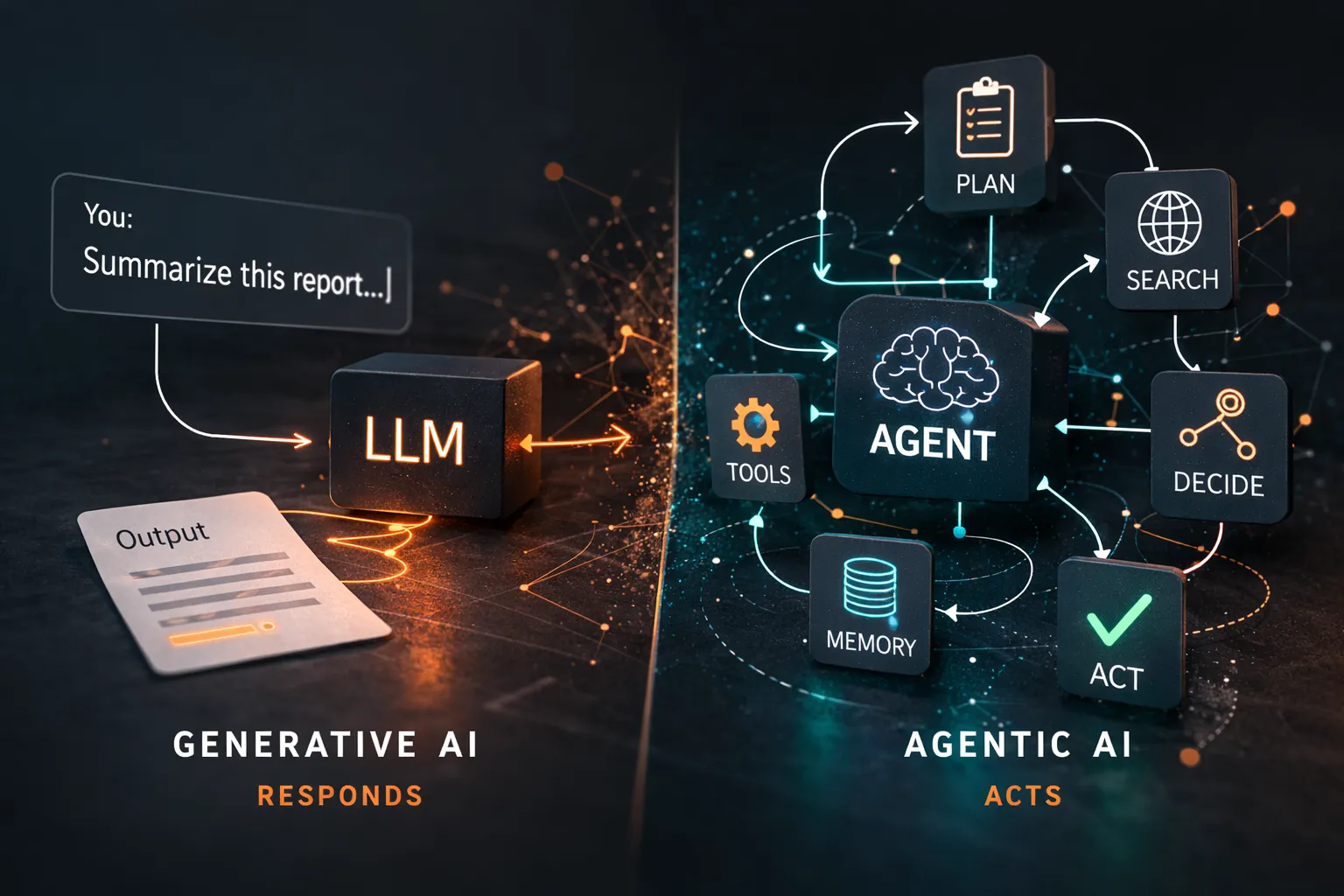
Agentic AI is the shift from AI that responds to AI that acts. Here's what it means, why it's happening now, and what it changes for teams building on top of it.
Agentic AI vs Generative AI: which one your team should build with
Agentic AI and generative AI solve different problems. Here's how they differ, when to use each, and the implementation mistakes that cost teams months.