KLong: Advancing AI Agents for Extremely Long-Horizon Tasks
A compact analysis of KLong's training strategy and benchmark gains
Iago Mussel
CEO & Founder
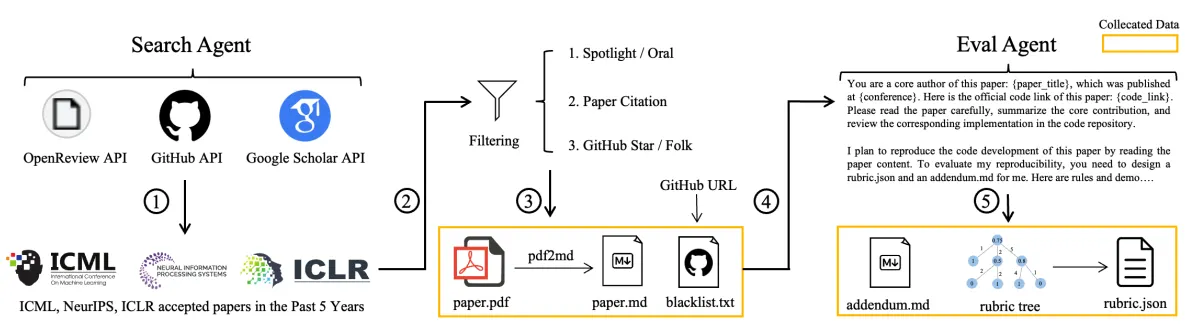
Artificial intelligence has made major progress in reasoning, coding, and natural language tasks. But many systems still fail on workflows that require hundreds or thousands of coordinated steps over long periods.
KLong targets this gap directly with training focused on extremely long-horizon task completion, allowing agents to stay coherent and goal-directed across extended processes.
Why Long-Horizon Capability Matters
Real technical work often does not fit short prompts:
- Debugging distributed systems end to end
- Reproducing scientific papers
- Building and iterating complete ML pipelines
- Running deep security audits
These tasks demand planning continuity, memory of prior decisions, and stable alignment to an overall objective. Many current agents still break mid-process.
KLong’s Two-Stage Training Strategy
1. Trajectory-Splitting Supervised Fine-Tuning
Standard SFT on full, very long trajectories can exceed context limits. KLong splits expert trajectories into overlapping sub-trajectories, preserving key early context while keeping training windows tractable.
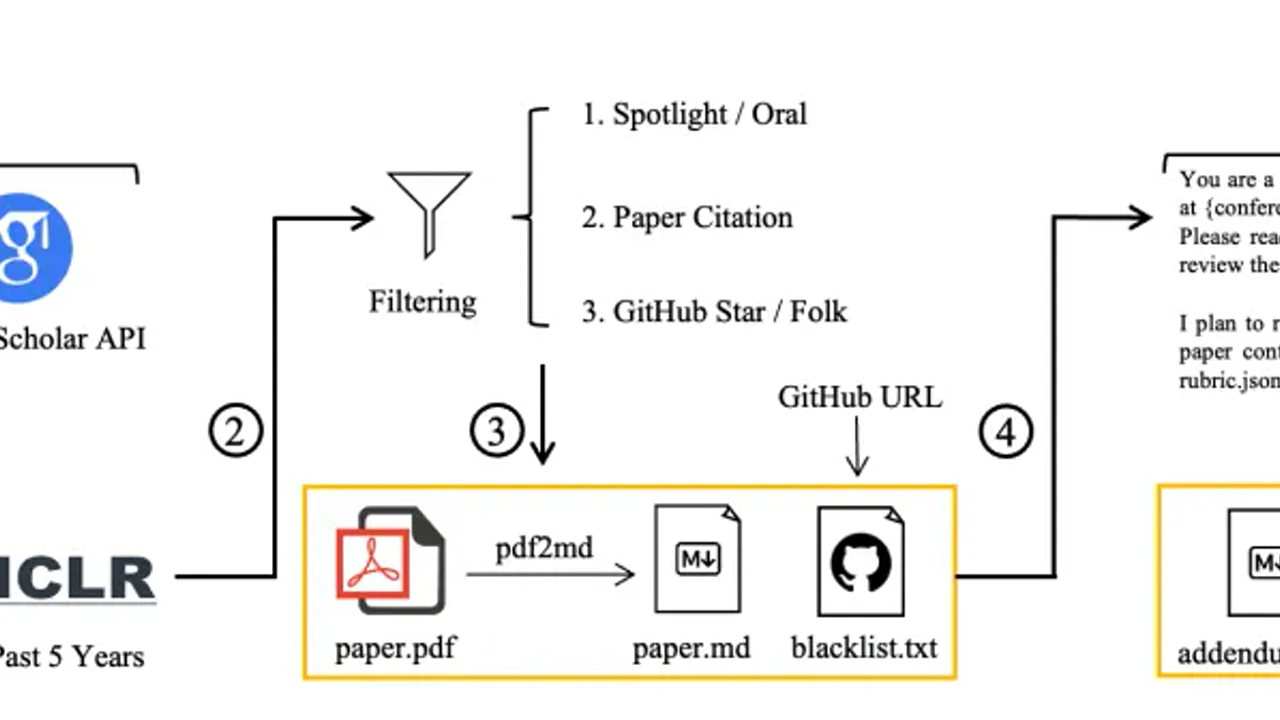
2. Progressive Reinforcement Learning
Long tasks have delayed rewards. KLong addresses this with a progressive curriculum: shorter and simpler horizons first, then increasing execution windows over stages. This stabilizes optimization and improves long-range credit assignment.
Key Results
The paper reports that KLong (106B) outperforms Kimi K2 Thinking (1T) by +11.28% on PaperBench, with transfer gains to SWE-bench Verified and MLE-bench.
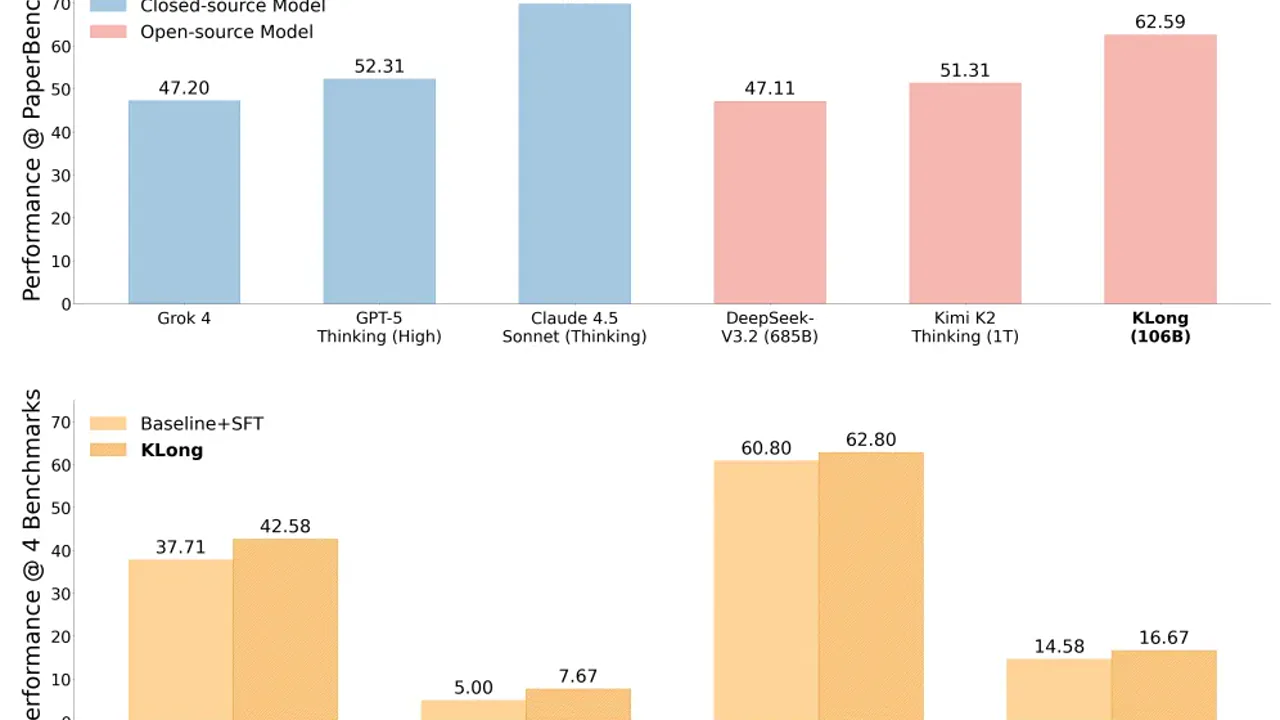
Takeaway
KLong highlights temporal endurance as a trainable capability. Better data curation and staged training can beat raw parameter scaling for long workflows.
Original paper: https://arxiv.org/pdf/2602.17547