IRon: A Token-Diet Agent That Treats Prompts Like Infrastructure (WIP)
Iago Mussel
CEO & Founder
You know the pattern:
- user writes a long request like a Jira ticket
- the model replies with a novel
- half the tokens are HTML/boilerplate/repeated constraints
- you pay for it every time
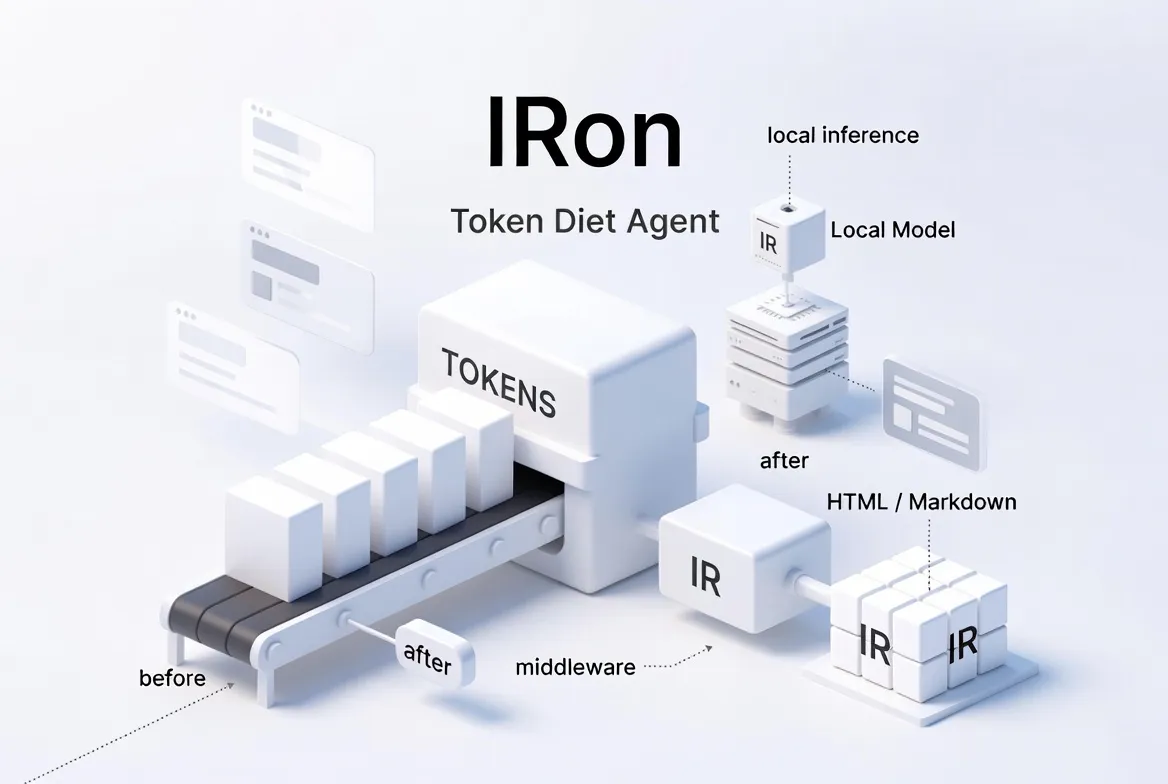
IRon is a work-in-progress Go CLI exploring a different approach: treat an LLM interaction like a server request lifecycle, with middlewares that can compress, enforce compact formats, and expand locally.
Repo (WIP): https://github.com/huntermussel/IRon.git
This is not a “prompt pack.” It’s an architecture: token control as a pipeline.
What IRon is (in one sentence)
A middleware-driven agent that tries to spend tokens only on reasoning, not on verbosity.
Or, more bluntly: IRon makes the model speak shorter languages (IRs), then converts them back into human-friendly outputs after the model finishes.
The mental model: like WordPress hooks, but for LLM calls
IRon treats a conversation step as an event stream, and lets middlewares hook into it:
before_llm_request: rewrite user input, inject minimal instructions/tools, clamp budgetsafter_llm_response: post-process model output, validate format, expand IR → finalbefore_user_reply: final formatting/redaction/UX decisions
Each middleware can observe, modify, block, or trigger reprompt.
If you’ve ever built a real web app, this should feel familiar.
The token-diet playbook (what IRon is aiming for)
1) Compress intent (keep constraints, drop the story)
Users often send narrative. Models don’t need narrative, they need:
- goal
- constraints
- output shape
- context references
So IRon tries to turn this:
“Can you build a landing page in React with a hero and CTA and testimonials, responsive, modern, componentized…”
into something more like:
intent: landing.react
req: hero, cta, testimonials
constraints: responsive, componentized, modern
output: emmet|tsxSame meaning. Fewer tokens. More predictable output.
2) Enforce compact outputs (IR instead of full payloads)
A huge chunk of cost is responses, not requests. If you ask for HTML, SQL, or scaffolded code, you often pay for standard boilerplate that could be generated deterministically.
IRon’s plan is to avoid this waste by forcing the model to output Domain Specific Languages (DSLs) and expanding them locally on the client-side (the Go CLI). This means the “heavy lifting” of string repetition happens on your machine, never touching the LLM’s context window or your bill.
Currently working (Experimental):
- HTML: Model outputs Emmet → IRon expands to HTML.
Planned for the future (Roadmap):
- Database: Model outputs DBML → IRon expands to SQL or Drizzle schemas.
- Backend: Model outputs Blueprint (or similar specs) → IRon runs
laravel newor Rails scaffolds.
Why tip the LLM in tokens for writing a CREATE TABLE statement you could have scaffolded in 1999?
Current tools spend a lot of tokens streaming characters that a deterministic compiler could write instantly. IRon aims to stop that.
3) Load only the middleware you need (avoid tool/schema inflation)
One of the easiest ways to waste tokens: injecting a big tool schema every time.
IRon aims to load middlewares conditionally. Example rule:
- load the Emmet middleware only if:
- user asks for HTML OR
- an HTML file is attached OR
- a tool call involves HTML content
No HTML request → no Emmet logic → no extra instructions.
4) Short-circuit trivial turns (0 tokens)
“Hi”, “thanks”, “ok” shouldn’t call an LLM.
IRon can answer those instantly. Not exciting, but it’s real savings.
5) Compact memory (keep relevance, not history)
Shipping full chat history is the fastest way to burn context.
IRon is moving toward:
- small recent window (raw)
- plus compact facts/decisions (compressed)
- plus selective retrieval for relevance
The rule is simple: context should be chosen, not accumulated.
Future Roadmap: Connecting the Ecosystem
We are expanding beyond just local files and CLI interactions. The goal is to bring the “token diet” philosophy to external tools and more providers.
Expanded Tool Support
We plan to treat external platforms as stream sources that can be compressed:
- Email & Slack: Summarize threads into compact “intent objects” before the model ever sees them.
- Notion: Convert verbose pages into structural outlines for context.
More Providers
While we started with Ollama for local, free development, we are building adapters for:
- OpenAI & Anthropic: For when you need maximum reasoning power (but still want to save on output tokens).
- Custom Endpoints: Connect to any OpenAI-compatible API.
Testing IRon with Ollama (local, cheap, repeatable)
Below is a pragmatic way to test IRon against a local model so you can iterate without burning API credits.
1) Install Ollama
Follow Ollama’s install instructions for your OS, then verify:
ollama --version2) Pull a model
Pick one that matches your hardware. For example:
ollama pull qwen2.5-coder:14b
# or
ollama pull llama3.1:8b3) Start Ollama (if it’s not already running)
Ollama usually runs as a service, but verify it’s responding:
curl -s http://localhost:11434/api/tags | head4) Run IRon against Ollama
IRon is still in development, so the exact flags may evolve. The typical pattern is:
- provider =
ollama - base URL =
http://localhost:11434 - model name = the one you pulled
Example shape (adjust to IRon’s current CLI):
# example only: adapt to IRon CLI flags
iron chat \
--provider ollama \
--base-url http://localhost:11434 \
--model qwen2.5-coder:14bIf IRon supports env vars instead:
export IRON_PROVIDER=ollama
export OLLAMA_HOST=http://localhost:11434
export IRON_MODEL=qwen2.5-coder:14b
iron chat5) Use a test prompt that triggers compression
Try something intentionally verbose:
“I want you to build a landing page. Use a hero section with headline + subtitle, a call to action button, and three testimonials. Make it responsive. Keep it minimal. Output HTML.”
If the Emmet bridge is enabled, you should see the model produce Emmet (or another compact IR) instead of full HTML—then IRon expands it.
6) Measure the savings (what to log)
Token measurement varies by provider, but you can still measure:
- raw prompt length (chars / approx tokens)
- response length
- IR length vs expanded output length
A useful debug mode is to write JSONL logs per step:
- original user text
- rewritten user text
- system/tool injection
- raw model response
- expanded final response
- estimated token counts
If IRon already emits debug logs, that’s where you’ll see immediate wins.
What to contribute (high-leverage dev tasks)
If you want to help, here are contributions that directly improve token economics:
✅ Middlewares that actually save tokens
- intent compressor: consistent slot-based rewrite with negation safety
- stopword cleaner: remove filler without breaking constraints
- budget clamp: dynamic
max_tokensbased on intent type - short-circuit rules: greetings/acks/help routing
✅ Format bridges (compact IR ↔ expanded output)
- HTML ↔ Emmet (and edge cases: attributes, forms, lists)
- DBML ↔ SQL/Drizzle: The biggest opportunity for backend token savings.
- Blueprint ↔ Laravel/Rails: Scaffolding logic so the LLM doesn’t have to write files manually.
- Markdown ↔ structured outline IR
✅ Tool schema minimization
- inject only relevant tools
- keep schemas short
- strip redundant descriptions
- compress tool outputs (truncate noise, keep signal)
How to help right now (practical steps)
If you’re a dev who likes building infrastructure-shaped tools:
- Run IRon locally with Ollama
- Pick one token-saving middleware
- Add debug logs that make savings obvious
- Open a PR with a minimal, testable change
- Document the “before vs after” prompt/response sizes
Even a small middleware that reliably removes 20–30% prompt bloat is meaningful over thousands of calls.
Closing thought
IRon is still evolving, but the direction is stable:
- treat LLM interaction as a pipeline
- use middleware hooks to control token shape
- speak compact formats to the model
- expand locally for humans
If that matches how you think about systems, you’ll probably enjoy contributing.