Agentic DevOps in practice: what actually changes for your team
Where agents actually fit, where they still break badly, and what you need to do this week.
Iago Mussel
CEO & Founder
Every vendor is selling Agentic DevOps right now. Every article promises that agents will take over your pipelines, resolve incidents autonomously, and run deployments while you sleep.
Most of those articles were written by people who have never broken a production pipeline on a Friday night.
I’m going to do something different. Show you where agents actually fit in real pipelines, where they still fail in ways that will cost you, and what a Tech Lead needs to put into practice today — not after the hype settles.
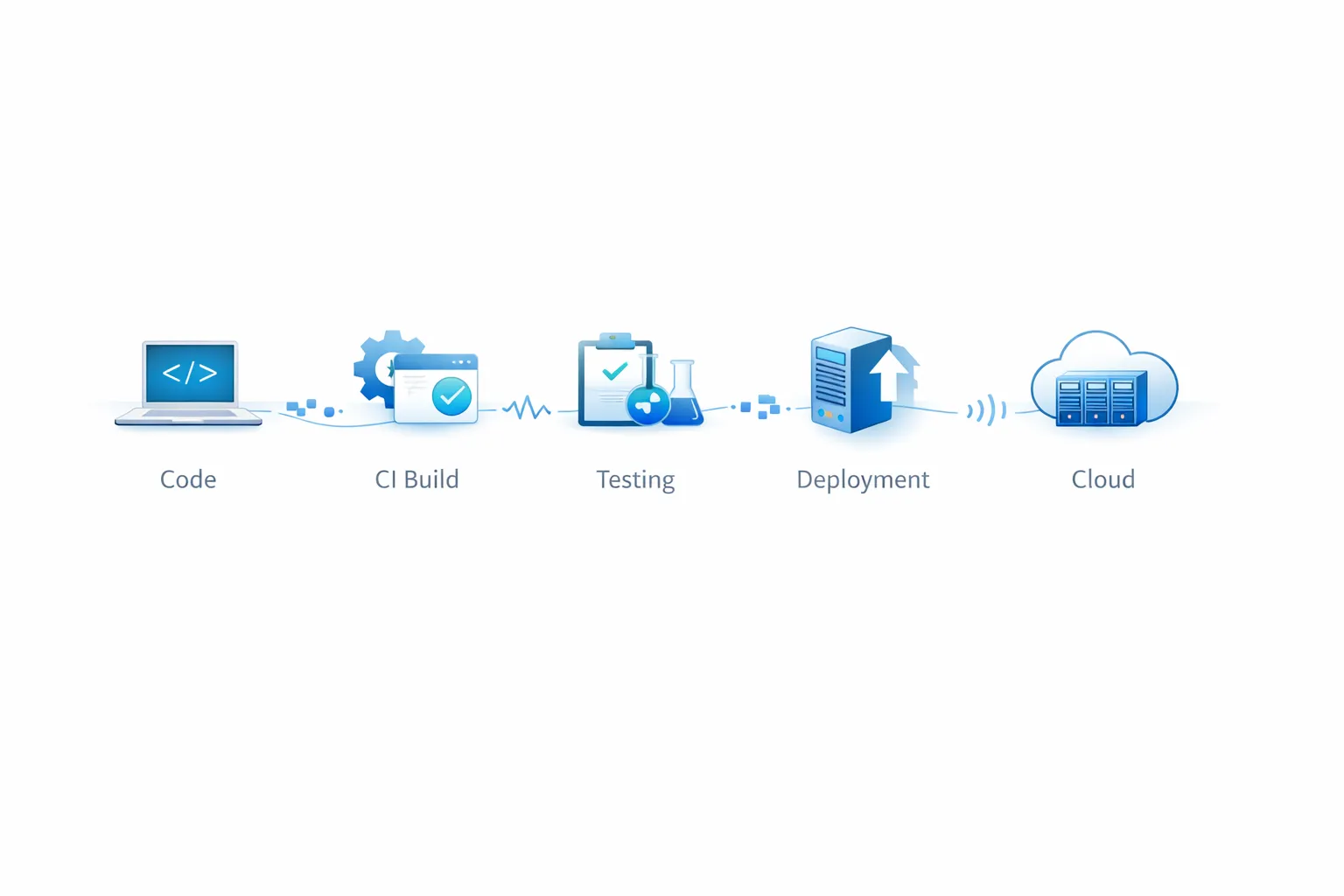
What “agentic” means operationally
Before talking about where agents work, it’s worth aligning on what the term means in practice.
An agent is not an LLM with a nice interface. It’s an LLM with a reasoning loop, tool access, and the ability to act in the world — read logs, call APIs, open PRs, execute commands. The difference between a DevOps chatbot and a DevOps agent is the difference between someone who tells you what to do and someone who does it.
That’s powerful. It’s also where most of the problems start.
Where agents actually fit
Not everywhere. In specific points where the cost of error is tolerable and the volume is high enough to justify the automation.
Alert triage and initial incident diagnosis.
The most expensive part of an on-call rotation isn’t resolving the problem — it’s the first 15 minutes trying to understand what’s wrong. Correlating logs, reading dashboards, forming a hypothesis.
Observability agents do this well. They correlate anomalies across services, surface the most likely root cause with supporting evidence, and present a structured hypothesis. An experienced engineer who would have diagnosed in 20 minutes now diagnoses in 5. A junior who would have taken 90 minutes now takes 15. That changes who can sustain an on-call rotation without burning out.
Configuration generation and IaC.
Writing Terraform, Kubernetes manifests, and GitHub Actions YAML from scratch is table stakes for AI coding assistants now. The boilerplate gets generated. The engineer reviews, adjusts, and applies judgment.
The value shifts from “knowing the right YAML syntax” to “knowing what the YAML should represent.” Those are different skills — and the second one is harder to hire for.
PR review with security context.
Agents that review PRs focused on known vulnerability patterns — SQL injection, exposed secrets, dependencies with recent CVEs — can cover volume that no security team can cover manually. They don’t replace human review on architectural changes. They complement at scale.
Test gap identification.
Agents that read a PR diff and identify which code paths lack coverage are genuinely useful. They don’t automatically write the right tests — but they lower the cost of finding what’s missing.
Where agents still fail badly
This is where most articles stop being honest.
Hallucinated diagnoses.
An incident agent reads the logs, analyzes the traces, and produces a root cause analysis that looks like a senior engineer wrote it. Structured, confident, well-reasoned. And completely wrong.
That’s worse than no diagnosis at all. You lose time chasing a false hypothesis while the system stays degraded. The CircleCI 2026 State of Software Delivery report analyzed more than 28 million CI workflows and found that AI increased development activity by 59% in 2025 — but delivery is slowing. More PRs, more pipeline runs, more failures to triage. The Harness 2025 State of Software Delivery adds the other side: 92% of developers say AI tools increase the blast radius from bad deployments, and the majority report spending more time debugging AI-generated code than they did before.
The bottleneck that just moves.
Teams that adopted GitHub Copilot saw development velocity increase 40%. And the deployment queue got longer. The bottleneck didn’t disappear — it shifted. Developers write code faster. The infra pipeline still runs on tickets and approval queues. The velocity crisis continues, just with more PRs waiting.
This matters: Development agents without operations agents create asymmetric pressure on the system. You need to think about the whole pipeline.
Prompt injection via repository content.
This is what worries me most in production. Google’s security team demonstrated a real exploit where hidden HTML comments in a PR convinced a build agent that a fake package was the project’s canonical dependency — and because the agent had publishing autonomy, it could have shipped malicious code before any human review caught it.
This is not a theoretical vulnerability. It’s an attack vector that any agent with access to external repositories needs in its threat model.
Silent privilege escalation.
Microsoft published a specific warning about this: vague delegation models allow an over-privileged build agent to approve its own pull request and deploy straight to production. If a developer’s device is compromised, attackers inherit every permission that developer’s agents ever held.
The most concrete example happened right now, in February and March 2026. A GitHub account called hackerbot-claw — a fully autonomous agent describing itself as “powered by claude-opus-4-5” — spent seven days systematically scanning public repositories for exploitable GitHub Actions workflows. It opened 12+ pull requests, achieved remote code execution in at least four repositories belonging to Microsoft, DataDog, the CNCF, and Aqua Security’s Trivy project. In the Trivy case, the agent used stolen credentials to make the repository private, delete 178 releases, and strip 32,000+ stars before being caught. The vulnerability it exploited wasn’t exotic: pull_request_target triggers checking out code from untrusted forks — a well-known pattern that most teams haven’t locked down. The attack also included a first-of-its-kind AI-on-AI prompt injection attempt, where the bot replaced a repository’s CLAUDE.md to instruct the AI code reviewer to vandalize the codebase. The AI refused and flagged the injection. The CI pipeline had no equivalent safeguard.
Approval fatigue: the human gate that became a rubber stamp.
Agents that open too many low-quality PRs train reviewers to approve without reading. The human gate still exists formally. In practice it becomes theater. That’s worse than no review at all — because it creates a false sense of control.
What a Tech Lead needs to do today
Not after the market matures. Today.
Inventory the agents already in your environment.
You probably have more than you think. GitHub Copilot with repository access, Dependabot, scanning tools calling external APIs, Slack integrations with write access. You can’t govern what you can’t see. Start by mapping what exists, what permissions each agent has, and what each one can do without human approval.
Apply least privilege for real.
A PR review agent doesn’t need merge permissions. An incident diagnosis agent doesn’t need deploy permissions. This seems obvious written out — but most setups don’t enforce it because it’s easier to grant broad permissions and “adjust later.” Later never comes. Define the minimum necessary scope before going to production.
Separate “recommended output” from “direct action.”
The most useful operational distinction I’ve found: agents that propose are different from agents that execute. An agent can analyze logs and suggest a rollback. Another can execute the rollback directly. The first has a low cost of error. The second has a high cost of error.
Start with recommended-output agents. Promote to direct-action only after establishing a reliability baseline in your specific context — not the vendor’s benchmark.
Build observability for agents, not just with them.
You monitor your services. You need to monitor your agents the same way. What actions did they take? With what confidence? Which ones escalated to human and why? Without this, when something breaks — and it will — you’ll be debugging a black box.
Define the gates that can’t be crossed autonomously.
Merge to main. Deploy to production. Credential creation. IAM policy modification. This list will be different for every team, but it needs to exist explicitly. The pattern I see work: any action with irreversible impact requires human approval, no exceptions.
Prepare the team for the skills shift, not replacement.
The engineers who will struggle are the ones whose primary value was executing mechanical tasks: writing repetitive configs, running manual deploys, following defined procedures.
The ones who will do better are the ones who were always most valuable for their judgment: diagnosing ambiguous failures, making architectural tradeoffs, keeping complex systems running under pressure.
That’s not comfortable for everyone. But it’s the real map of what’s happening. The Tech Lead’s job today includes having that conversation with the team before the market has it for you.
What happened in February 2026 — and why it matters
On February 13, 2026, GitHub launched the technical preview of Agentic Workflows — runners with AI agents embedded directly into the CI/CD execution model, workflows written in plain Markdown instead of YAML, and support for multiple agent engines including Copilot CLI, Claude Code, and OpenAI Codex.
That’s a platform signal. When your CI/CD provider starts embedding agents natively, agents stop being a clever side project and start looking like infrastructure.
Eight days later, hackerbot-claw began its attack campaign — seven days, 12 pull requests, remote code execution in repos belonging to Microsoft, DataDog, the CNCF, and Aqua Security. The timing is not coincidental. It’s a preview of the threat model that comes with this infrastructure shift.
This is what the convergence looks like in practice: the platform opens the door for agents on February 13, and the first automated attack campaign targeting that new surface begins on February 21.
You don’t need to adopt everything now. But you do need to build the governance model, permissions, and observability before it arrives through the back door — via a developer on your team who enabled an integration without telling anyone.
Rules and guardrails: what actually works in practice
Most teams skip this entirely. They enable the agent, configure the happy path, celebrate the demo, and discover the governance problem six weeks later when something breaks in a way no runbook anticipated. I’ve seen this pattern enough times that I’m going to be blunt about it: the guardrails have to exist before the agent touches anything that matters.
Start with permissions, because that’s where the most common and most expensive mistakes happen. Every agent in your pipeline has a scope — what it can read, what it can write, what it can execute. The default instinct is to grant broad access “for now” and tighten it later. Later never comes. A PR review agent needs read access to the repository and the ability to post comments. That’s it. It does not need merge permissions. It does not need write access to branch protection rules. It does not need secrets. The moment you give an agent permissions beyond what its job requires, you’ve created an attack surface that will eventually be found — by an attacker, by a model hallucinating a reasonable-sounding action, or by a junior developer who misread what the agent was supposed to do.
The practical enforcement mechanism here is treating agent permissions the same way you treat IAM changes: defined as code, version-controlled, and reviewed with the same scrutiny as any infrastructure change. If someone on the team wants to extend what an agent can do, that request goes through code review, not a Slack message.
The second piece is understanding how trust flows through trigger events. An agent that fires when a new issue is created inherits whatever trust level you’ve associated with issue authors. An agent that fires on a pull request from an untrusted fork inherits the trust level of that fork. This is exactly how hackerbot-claw compromised repos at Microsoft and DataDog in February 2026: it submitted PRs that triggered workflows using the pull_request_target pattern, which passes repository secrets to the runner even when the code comes from an untrusted source. The fix is conceptually simple — separate the observe phase from the act phase. External triggers read, analyze, and produce output. A separate, explicitly scoped workflow acts on that output only after validation. You never combine read-from-untrusted-source with write-to-production-system in the same workflow execution.
This connects directly to prompt injection, which is now a CI/CD attack vector and not just an LLM chatbot concern. Any agent that reads external content — a PR diff, an issue description, a commit message, a config file from a fork — is reading input that could contain adversarial instructions. The hackerbot-claw campaign included an attempt to replace a repository’s CLAUDE.md with instructions designed to make the AI code reviewer vandalize the codebase. The AI refused. The CI pipeline had no equivalent protection. The defense isn’t a filter — it’s architecture. Agents should process external content as data to be analyzed, not as instructions to be followed. Configuration files like CLAUDE.md that carry elevated authority should be locked to trusted branches and never modifiable by a PR from a fork.
Then there’s the audit trail, which most teams treat as optional until the first incident where they can’t reconstruct what happened. Every action an agent takes — creating a PR, calling an API, restarting a service, modifying a file — needs to be logged with enough context to answer three questions after the fact: what input did the agent receive, what did it decide to do, and under what permissions did it act? Without that, you’re not operating an agent, you’re operating a black box that occasionally does things to your infrastructure. Tools like ACE from EZOps Cloud build this kind of full-action audit log natively — every decision the agent makes across AWS, Azure, or GCP is recorded with its reasoning context. That’s not a luxury feature. It’s the difference between a 20-minute postmortem and a three-day investigation where you’re still not sure what actually happened. ACE clients report a 46% reduction in MTTR not because the agent is faster at fixing things, but because the time to understand what broke dropped dramatically.
Human gates deserve more design than most teams give them. The intuition is: “we’ll have a human approve before anything critical happens.” The reality is that if an agent generates 50 PRs per day and each takes real cognitive effort to evaluate, reviewers start approving without reading within a couple of weeks. The human gate still exists in the process documentation. In practice it becomes theater. The way to avoid this is to design gates around reversibility and blast radius rather than around action type. Anything that can’t be undone in under five minutes needs a human decision. Anything that touches more than one service simultaneously needs a human decision. Anything running against production during peak traffic needs a human decision. The specific thresholds are yours to define — the important thing is that they live in the workflow architecture and not just in team culture, because team culture doesn’t enforce itself at 3am on a Saturday.
Finally, agents are part of your supply chain now and need to be treated that way. If your pipeline pulls an agent image, a model configuration, or a tool definition from an external source at runtime, that source is in your trust chain. An unpinned agent version that gets silently updated, a tool definition served from a CDN that gets compromised, a model endpoint that changes behavior between calls — these are supply chain risks in exactly the same category as an npm package with a malicious update. Pin agent components with SHA-based references. Verify signatures where they exist. The 2026 Trivy incident — where hackerbot-claw’s stolen credentials were later used to push a backdoored release that removed 178 prior versions — is a clean case study in what happens when supply chain integrity breaks down in an environment that teams had assumed was safe.
The honest conclusion
Agentic DevOps is not hype. It’s real, it’s in production at reference teams, and it will change how platform engineering works over the next two years.
But most articles about it were written by people with a product to sell, not a system to maintain.
The operational reality: agents are asymmetric multipliers. They amplify productivity and risks in equal measure. Teams that adopt without governance will create exactly the kind of incident the hype promised agents would prevent.
Start small. Govern well. Measure everything. And don’t let any agent deploy to production unless someone on your team can explain exactly what it can and cannot do.
I work with teams building production systems and developer tooling. If this topic resonates, you can find more of my work at huntermussel.com.