Agentic AI vs Generative AI: the real difference for teams that need to implement
One responds. The other acts. The difference matters when you're building.
Iago Mussel
CEO & Founder
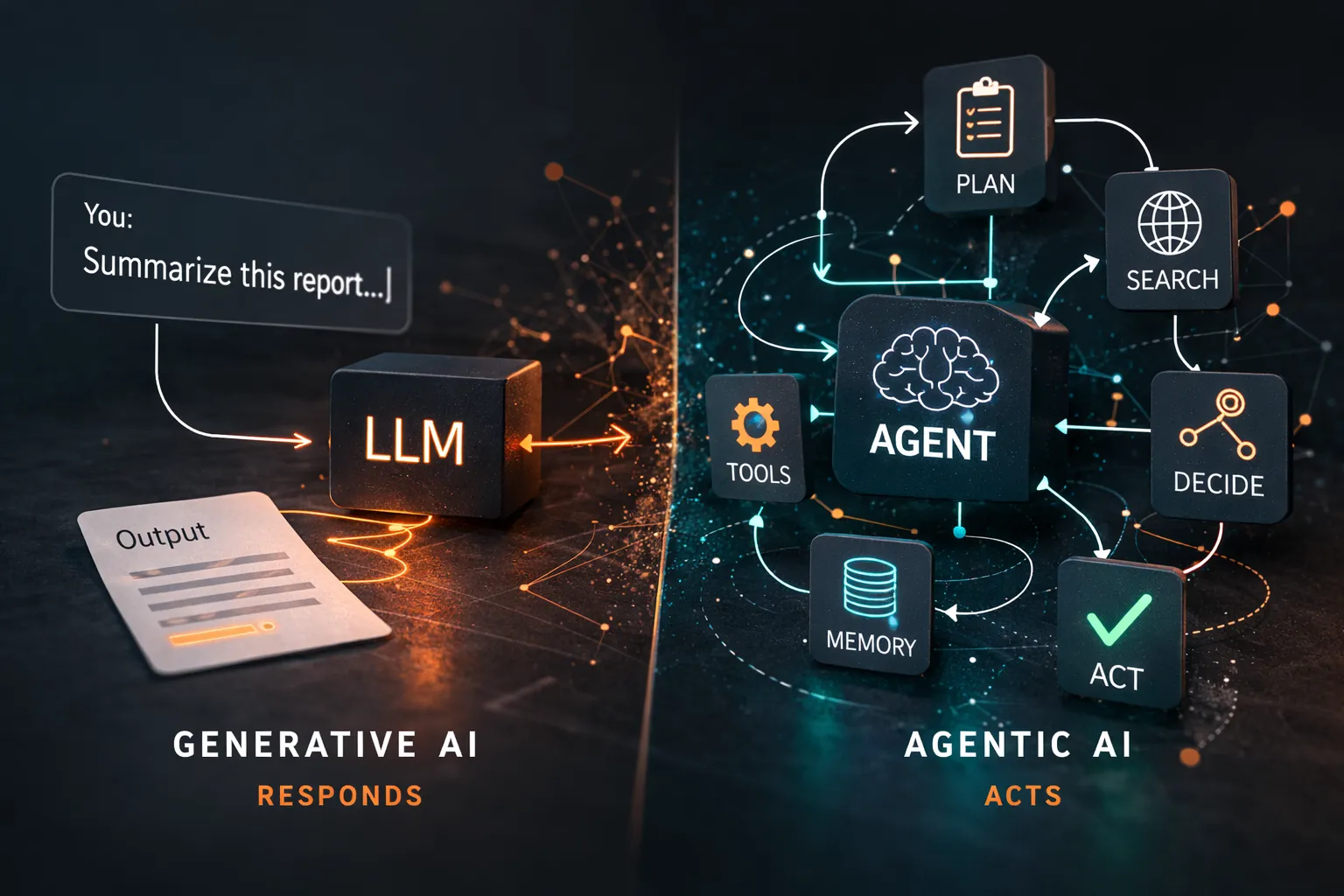
Both terms appear in the same conversations, the same vendor decks, and the same budget requests. Most teams use them interchangeably.
They’re not the same. And the distinction matters when you’re making an implementation decision because building with the wrong mental model produces systems that either underperform or over-promise. I’ve watched both happen.
Generative AI: the foundation
Generative AI refers to models that produce output: text, code, images, audio.. based on a prompt and learned patterns from training data. You know when you’re typing on your smartphone and your keyboard suggests the next words? LLM’s are an evolution of that.
When you call an LLM API with a prompt, that’s generative AI. The model takes in a context window of tokens and produces the next most probable sequence. It’s sophisticated autocomplete powered by patterns learned from a massive corpus.
Key properties you need to understand:
- Stateless by default. Each call is independent. The model has no memory of previous conversations unless you explicitly pass conversation history in the prompt.
- Single-turn. One input, one output. The model responds to what you send and stops.
- No external state. The model can’t read files, call APIs, query databases, or take any action in the world unless you build that plumbing separately.
- Probabilistic. The same prompt can produce different outputs on different calls. This is intentional, it’s how the model generates creative, contextual responses rather than rote repetition.
This is what most teams deployed in 2023–2024: a language model embedded in a product, answering questions, generating content, helping with writing or code. Extremely valuable. But bounded by the single-turn, no-memory, no-action model.
Agentic AI: adding the loop
Agentic AI takes a generative model and adds structure around it that enables multi-step, goal-directed behavior.
The core additions:
Tools. The agent can call external systems — APIs, databases, code execution environments, web search, file systems. It can take actions, not just produce text. Today, we have many ways to do this, using function calling, MCP, or even an OpenAPI JSON schema.
A reasoning loop. Instead of single-turn prompt → response, the agent evaluates a goal, selects an action, executes it, observes the result, and decides the next action. This loop continues until the goal is met or a termination condition is reached.
Memory. Short-term: the agent maintains context across the steps of a single task. Long-term (optionally): persistent memory across sessions, stored in a vector database or structured store.
Planning. For complex goals, the agent can decompose a task into sub-tasks, execute them in sequence or in parallel, and synthesize the results.
The result is a system that can execute a goal like “review the past 30 days of customer support tickets, identify the top 5 recurring issues, and draft a summary with proposed solutions” without a human orchestrating each step.
The implementation difference
This distinction is concrete when you’re building.
Building with generative AI:
response = client.messages.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": prompt}]
)
return response.contentYou construct a prompt. You get a response. You display it, store it, or pass it to the next step in your application logic. Your application code is the orchestrator.
Building with agentic AI:
agent = Agent(
model="claude-opus-4-6",
tools=[search_tool, database_tool, email_tool],
system="You are a research assistant. Use the available tools to complete the user's goal."
)
result = agent.run(goal="Research Q1 competitors and prepare a brief for the product team")The agent determines which tools to call, in what order, based on what it discovers. Your application code sets the goal and the tool boundaries, the agent handles the execution plan.
The programming model is different. The failure modes are different. The testing approach is different.
Choosing the right model for your use case
Use generative AI when:
- The task is well-defined and single-step
- You need deterministic behavior ( same input, same output )
- The user is the orchestrator ( they’re driving a conversation or asking discrete questions )
- Latency requirements are tight (multi-step agents add latency)
- You need to minimize cost (each agent loop iteration costs tokens)
Use agentic AI when:
- The goal requires multiple steps that depend on each other
- The path to the goal isn’t known in advance — the agent needs to adapt based on what it finds
- The task involves interacting with external systems (reading, writing, querying)
- The complexity of orchestration would otherwise sit in brittle application code
The mistake teams make
The most common mistake I see: building agentic architecture when the use case only needs generative AI.
An agent is not an upgrade from a simple LLM call. It’s a different system with different complexity, cost, latency, and failure modes. If your task is single-step, don’t build a loop around it.
The second most common mistake: building a generative AI integration when the task actually requires multi-step execution — and then watching the system fail because it can’t take actions or maintain context across steps.
The architecture should match the task. Not the trend.
I work with teams building production systems and developer tooling. If this topic resonates, you can find more of my work at https://huntermussel.com.